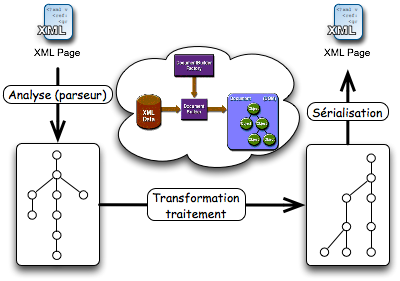
DOM : un standard du W3C1 IntroductionDOM est un standard proposé par le W3C. DOM signifie "Document Object Model". Comme son nom l'indique, c'est un standard permettant de représenter des documents (HTML ou XML) sous la forme d'une hiérarchie d'objets. Le document chargé en mémoire est structuré en arbre dont les noeuds sont des instances de classes (au sens de la programmation objet) normalisées. Celles-ci proposent de nombreuses méthodes permettant de manipuler le document en mémoire. |
| Un schéma d'exploitation assez classique d'un document XML par l'API DOM peut être décrit par le schéma ci-contre. Un document XML est chargé en mémoire par un "parser" qui effectue l'analyse (et la validation) du document et qui construit l'arbre en mémoire. A noter que, à ce niveau, est souvent utilisé l'API SAX qui sera présenté dans la section SAX. Ensuite, à l'aide des méthodes disponibles, et seulement avec celles-ci, l'arbre est exploré et transformé. Finalement, cette structure est enregistrée dans un fichier (sérialisée). | |
Il existe plusieurs versions du standard DOM. Dans ce cours, nous ne présenterons que le DOM Level 2 qui est la plus courante dans les langages de programmation.
La hiérarchie DOM contient un ensemble d'une vingtaine de classes dont la structure est donnée ci-dessous. Cette structure, assez simple, cache une richesse en terme d'attributs et de méthodes. Dans la suite de cette section, nous allons les explorer rapidement. Notre présentation ne sera que succincte et le standard DOM fait partie intégrante du cours et donc doit être lu avec attention. Chaque classe présentée sera repérée par une coloration dans l'arbre-exemple et nous détaillerons les principaux attributs et méthodes de la classe. Ces derniers seront présentés, comme dans le standard, dans le langage IDL [1].
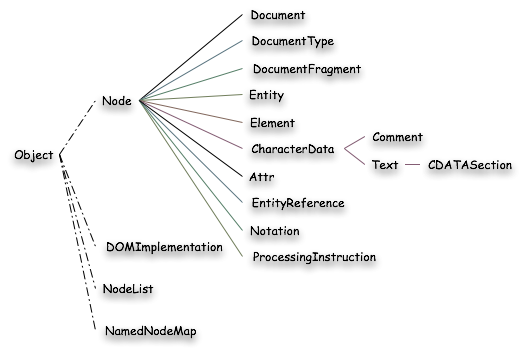
La classe "Node" est la classe de base de la structure. Tous les noeuds de l'arbre sont basés sur cette classe. Dans notre arbre-exemple ci-dessous, les noeuds "Node" sont colorés en orange.
"Node" comprend un ensemble de constantes permettant de "typer" le noeud courant (voir code ci-dessous). Évidemment, nous le verrons, il y a une redondance avec le nom de la classe de ce même noeud qui sera une sous-classe de "Node".
Remarque : dans le standard DOM, les informations sont souvent assez redondantes. Nous aurons l'occasion d'y revenir plus loin.
interface Node {
// NodeType
const unsigned short ELEMENT_NODE = 1;
const unsigned short ATTRIBUTE_NODE = 2;
const unsigned short TEXT_NODE = 3;
const unsigned short CDATA_SECTION_NODE = 4;
const unsigned short ENTITY_REFERENCE_NODE = 5;
const unsigned short ENTITY_NODE = 6;
const unsigned short PROCESSING_INSTRUCTION_NODE = 7;
const unsigned short COMMENT_NODE = 8;
const unsigned short DOCUMENT_NODE = 9;
const unsigned short DOCUMENT_TYPE_NODE = 10;
const unsigned short DOCUMENT_FRAGMENT_NODE = 11;
const unsigned short NOTATION_NODE = 12;
Ensuite, "Node" comprend un certain nombre d'attributs permettant de décrire le noeud, mais aussi de naviguer dans la structure.
readonly attribute DOMString nodeName; attribute DOMString nodeValue; //raises(DOMException) on setting/retrieval readonly attribute unsigned short nodeType; readonly attribute Node parentNode; readonly attribute NodeList childNodes; readonly attribute Node firstChild; readonly attribute Node lastChild; readonly attribute Node previousSibling; readonly attribute Node nextSibling; readonly attribute NamedNodeMap attributes; readonly attribute Document ownerDocument; readonly attribute DOMString namespaceURI; attribute DOMString prefix; //raises(DOMException) on setting readonly attribute DOMString localName;
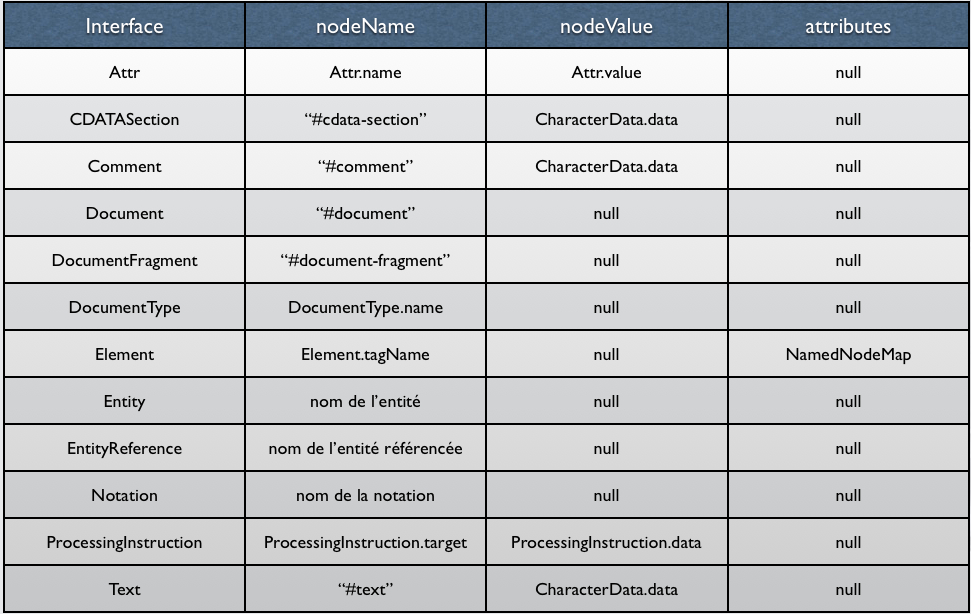
La description d'un noeud se fait par 3 attributs : "nodeValue", "nodeName" et "attributes". Selon le type de noeud rencontré, ces attributs prennent différentes valeurs. Le tableau suivant décrit les combinaisons possibles et les valeurs.
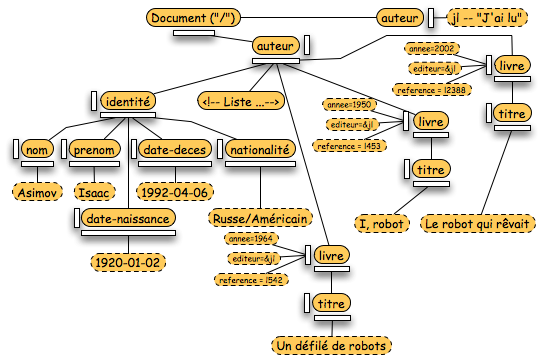
De nombreux attributs permettent de structurer le document (comme la figure ci-dessous le montre). Pour chaque noeud, il existe une référence au noeud père, aux noeuds frères qui l'entourent, aux noeud fils... Ces mêmes noeuds référencent aussi le noeud étudié.
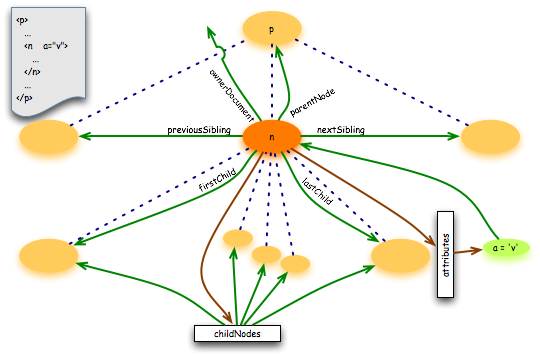
Compte-tenu de la complexité de l'architecture (du "sac de noeuds" que cela produit), il est inimaginable de manipuler un noeud directement. Aussi, DOM propose pour "Node" un ensemble de méthodes permettant de manipuler ces noeuds. Ce sont les seuls moyens de transformer le document. Elles permettent, de manière cachée, de tenir à jour tous les liens entre les différents noeuds et d'éviter des problèmes de référence avec les effets de bord désastreux associés.
Node insertBefore(in Node newChild,
in Node refChild)
raises(DOMException);
Node replaceChild(in Node newChild,
in Node oldChild)
raises(DOMException);
Node removeChild(in Node oldChild)
raises(DOMException);
Node appendChild(in Node newChild)
raises(DOMException);
boolean hasChildNodes();
Node cloneNode(in boolean deep);
void normalize();
boolean isSupported(in DOMString feature,
in DOMString version);
boolean hasAttributes();
};
Pour illustrer la manipulation d'arbres DOM, par exemple, prenons deux documents "A" et "B". Soit "a" un noeud de "A" et "b" un noeud de "B". Supposons que "a'" soit un fils de "a" et que l'on voudrait que "b" ait aussi comme fils "a'". Alors, il faut faire : "b.appendChild(a1.cloneNode(true))". Le booléen de la méthode "cloneNode" indique qu'il faut non seulement copier "a'" mais aussi tout le sous-arbre dont "a'" est la racine.
Passons maintenant à une rapide description des sous-classes de "Node".
A la racine de la hiérarchie, se trouve un noeud "Document". La figure suivante localise (en orange) ce noeud sur notre exemple. Chaque noeud de l'arbre référence ce noeud par l'intermédiaire de l'attribut "ownerDocument".
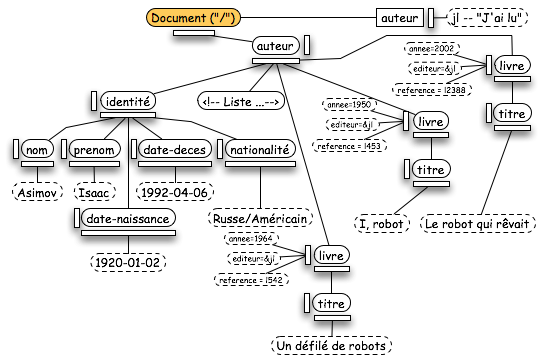
Cette classe possède des attributs faisant référence à la DTD utilisée et, bien sûr, à l'élément racine du document. Le code IDL suivant décrit les attributs et les méthodes de "Document".
interface Document : Node {
readonly attribute DocumentType doctype;
readonly attribute DOMImplementation implementation;
readonly attribute Element documentElement;
Element createElement(in DOMString tagName) raises(DOMException);
DocumentFragment createDocumentFragment();
Text createTextNode(in DOMString data);
Comment createComment(in DOMString data);
CDATASection createCDATASection(in DOMString data) raises(DOMException);
ProcessingInstruction createProcessingInstruction(in DOMString target,
in DOMString data)
raises(DOMException);
Attr createAttribute(in DOMString name) raises(DOMException);
EntityReference createEntityReference(in DOMString name) raises(DOMException);
NodeList getElementsByTagName(in DOMString tagname);
Node importNode(in Node importedNode,
in boolean deep)â
raises(DOMException);
Element createElementNS(in DOMString namespaceURI,
in DOMString qualifiedName)
raises(DOMException);
Attr createAttributeNS(in DOMString namespaceURI,
in DOMString qualifiedName)
raises(DOMException);
NodeList getElementsByTagNameNS(in DOMString namespaceURI,
in DOMString localName);
Element getElementById(in DOMString elementId);
};
Parmi les méthodes disponibles, nous pouvons distinguer deux classes majeures :
Les méthodes d'exploration sont extrêmement pratiques pour parcourir un document en mémoire. En effet, deux solutions se présentent : soit il faut parcourir le document en suivant les références (Cf. classes "Node") soit le parcours est "délégué" aux méthodes "getElementsByTagName" (récupérer tous les éléments de même nom) ou "getElementById" (récupérer l'élément ayant cet identifiant, s'il existe). Il est évident que la seconde solution est plus pratique du point de vue programmation et mise au point, mais elle peut s'avérer plus coûteuse en temps de traitement que la première méthode "à la main".
Laissons, le temps de ce paragraphe, les classes "Node" pour aborder deux classes importantes dans DOM : "NodeList" et "NamedNodeMap". Ces deux classes permettent de fournir des structures de données basiques : une liste ordonnée pour la première et un tableau associatif pour la seconde. Dans notre exemple, les "NodeList" sont en orange (boites horizontales) et les "NamedNodeMap" sont en vert (boites verticales).
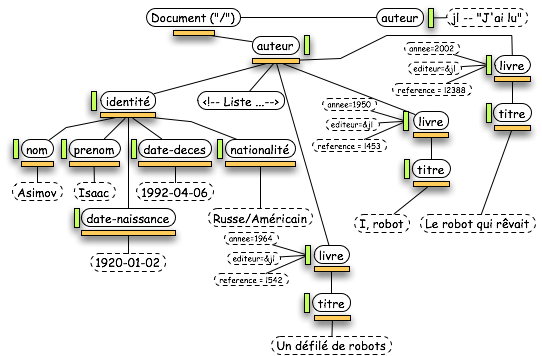
Ces deux classes ont des attributs et des méthodes très classiques par rapport aux structures de données qu'elles représentent. Elles sont utilisées à plusieurs niveaux :
interface NodeList {
readonly attribute unsigned long length;
Node item(in unsigned long index);
};
interface NamedNodeMap {
readonly attribute unsigned long length;
Node getNamedItem(in DOMString name);
Node setNamedItem(in Node arg)
raises(DOMException);
Node removeNamedItem(in DOMString name)
raises(DOMException);
Node item(in unsigned long index);
Node getNamedItemNS(in DOMString namespaceURI,
in DOMString localName);
Node setNamedItemNS(in Node arg)
raises(DOMException);
Node removeNamedItemNS(in DOMString namespaceURI,
in DOMString localName)
raises(DOMException);
};
Revenons maintenant aux noeuds de l'arbre XML en mémoire. Un des noeuds les plus courants est le noeud "Element". Dans l'arbre-exemple, ces noeuds sont colorés en orange.
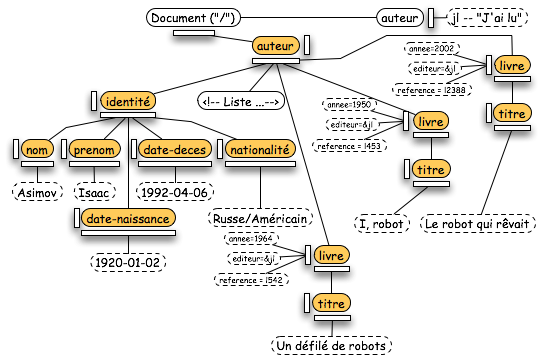
Dans cette classe, se trouvent toutes les méthodes pour manipuler les attributs d'un élément (avec ou sans les espaces de noms). A noter aussi la présence, comme dans "Document", de la méthode "getElementsByTagName(...)". Cette méthode fonctionne de la même manière que dans "Document" avec une limitation de "la zone de recherche" au sous-arbre dont cet élément est la racine.
interface Element : Node {
readonly attribute DOMString tagName;
DOMString getAttribute(in DOMString name);
void setAttribute(in DOMString name, in DOMString value)
raises(DOMException);
void removeAttribute(in DOMString name)
raises(DOMException);
Attr getAttributeNode(in DOMString name);
Attr setAttributeNode(in Attr newAttr)
raises(DOMException);
Attr removeAttributeNode(in Attr oldAttr)
raises(DOMException);
NodeList getElementsByTagName(in DOMString name);
DOMString getAttributeNS(in DOMString namespaceURI, in DOMString localName);
void setAttributeNS(in DOMString namespaceURI, in DOMString qualifiedName,
in DOMString value)
raises(DOMException);
void removeAttributeNS(in DOMString namespaceURI, in DOMString localName)
raises(DOMException);
Attr getAttributeNodeNS(in DOMString namespaceURI, in DOMString localName);
Attr setAttributeNodeNS(in Attr newAttr)
raises(DOMException);
NodeList getElementsByTagNameNS(in DOMString namespaceURI,
in DOMString localName);
boolean hasAttribute(in DOMString name);
boolean hasAttributeNS(in DOMString namespaceURI, in DOMString localName);
};
Il est maintenant possible de présenter un premier exemple de pseudo-code utilisant DOM sur notre exemple "fil rouge". Le code ci-dessous parcourt la structure "à la main" pour afficher le nom des différents éléments XML présents [2].
//Procédure récursive d'exploration de l'arbre DOM
Procédure parcours(Element e) {
//Affichage du nom de l'élément
Écrire(e->tagName);
//Parcours des fils de l'élément à la recherche des éléments fils pour les explorer
NodeList l = e->childNodes;
PourTout Entier i Dans [0..(l->length - 1)] Faire {
Node n = l->item(i);
Si n->nodeType == Node::ELEMENT_NODE Alors parcours(Element(n));
}
}
//Utilisation de la procédure
Document doc = créer Document();
doc->charger("ex_asimov.xml");
parcours(doc->documentElement);
Ce qui donne à l'affichage :
auteur identité nom prenom date-naissance date-deces nationalite livre titre livre titre livre titre
Dans cet autre exemple (ci-dessous), nous cherchons à afficher les éléments "titre" du document [3].
//Procédure récursive de recherche des éléments "titre"
Procédure rechercheTitre(Document doc, Element e) {
//Est-ce un élément titre ?
Si e->tagName == "titre" Alors Écrire(doc->versXML(e));
Sinon {
//Explorer alors les fils pour en trouver
NodeList l = e->childNodes;
PourTout Entier i Dans [0..(l->length - 1)] Faire {
Node n = l->item(i);
Si n->nodeType == Node::ELEMENT_NODE Alors parcours(Element(n));
}
}
}
//Utilisation de la procédure de recherche
Document doc = créer Document();
doc->charger("ex_asimov.xml");
rechercheTitre(doc, doc->documentElement);
Plutôt que de parcourir la structure, il est possible d'utiliser la méthode spécifique pour la recherche d'éléments. Le code ci-dessous illustre l'utilisation de cette méthode.
NodeList l = doc->getElementsByTagName("titre");
PourTout Entier i Dans [0..(l->length - 1)] Faire {
Écrire(doc->versXML(l->item(i)));
}
Ce qui donne à l'affichage :
<titre>Un défilé de robots</titre> <titre>I, robot</titre> <titre>Le robot qui rêvait</titre>
Maintenant que l'élément est défini, passons aux informations attachées à cet élément : les attributs. Contenus dans la liste des attributs (une NamedNodeMap), les attributs sont représentés par la classe "Attr". Les noeuds "Attr" sont colorés en orange dans l'arbre ci-dessous.
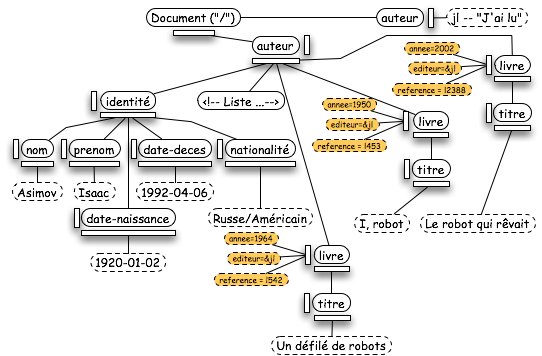
Concrètement, cette classe est un couple composé du nom de l'attribut ("name") et de sa valeur ("value"). Dans cette classe, "specified" indique si cet attribut est présent dans le document d'origine ou s'il a été ajouté grâce au schéma (DTD, XSD...) en attribut par défaut.
interface Attr : Node {
readonly attribute DOMString name;
readonly attribute boolean specified;
attribute DOMString value;
// raises(DOMException) on setting
readonly attribute Element ownerElement;
};
Pour terminer le tour des principales structures de DOM, nous abordons maintenant les structures textuelles (autres que les valeurs d'attribut évoquées au paragraphe précédent). Dans l'arbre ci-dessous, les noeuds "textes" sont colorés en vert et en orange (nous verrons la signification des couleurs plus loin).
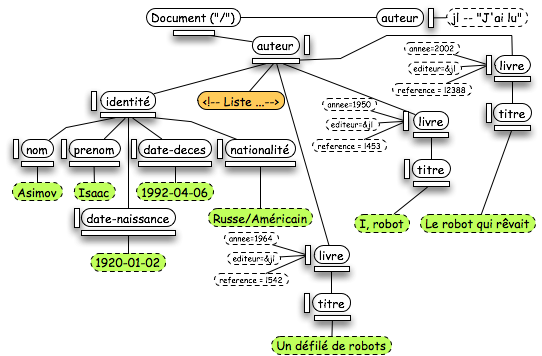
Toutes les informations textuelles sont regroupées sous un même classe : "CharacterData". Cette classe regroupe toutes les méthodes classiques de manipulation des chaînes de caractères.
interface CharacterData : Node {
attribute DOMString data;
// raises(DOMException) on setting
// raises(DOMException) on retrieval
readonly attribute unsigned long length;
DOMString substringData(in unsigned long offset,
in unsigned long count)
raises(DOMException);
void appendData(in DOMString arg)
raises(DOMException);
void insertData(in unsigned long offset,
in DOMString arg)
raises(DOMException);
void deleteData(in unsigned long offset,
in unsigned long count)
raises(DOMException);
void replaceData(in unsigned long offset,
in unsigned long count,
in DOMString arg)
raises(DOMException);
};
Le contenu textuel d'un élément est mémorisé par une classe "Text". Dans l'arbre exemple ci-dessus, ces noeuds sont en vert. Il existe aussi un cas particulier de noeud texte : la section CDATA. Dans DOM, elle est associée à la classe "CDATASection", sous classe de "Text".
interface Text : CharacterData {
Text splitText(in unsigned long offset)
raises(DOMException);
};
interface CDATASection : Text {
};
Enfin, un autre élément XML textuel est représenté dans DOM : les commentaires (en orange ci-dessus). En DOM, un commentaire correspond à la classe "Comment".
interface Comment : CharacterData {
};
Pour illustrer les classes "CharacterData", voici un nouvel exemple de programme en pseudo-code utilisant DOM. L'objectif de cet exemple est tout simplement d'afficher le contenu des noeuds textes de notre exemple "fil rouge".
//Parcours récursif des noeuds de l'arbre à la recherche des noeuds textes
Procédure parcoursTexte(Element e) {
Si ((e->nodeType == TEXT_NODE) ou (e->nodeType == COMMENT_NODE))
Alors Écrire(a->data);
Sinon PourTout Noeud n Dans e->childNodes Faire parcours(n);
}
//Appel de la fonction de parcours sur l'exemple
doc = créer Document();
doc->charger("ex_asimov.xml");
parcoursTexte(doc->documentElement);
Le résultat de cet exemple d'algorithme donnera l'affichage ci-dessous. Nous pouvons constater que le texte est affiché (heureusement), mais avec beaucoup d'espaces et de retours à la ligne entre chaque texte. Non, ce n'est pas un problème d'affichage de ce cours ou un problème avec le traitement de texte utilisé. Concrètement, l'exemple utilisé est mis en forme afin de le rendre lisible pour un humain. Des tabulations (ou des espaces) ainsi que des retours à la ligne ont été positionnés afin de présenter convenablement le texte XML. Lors de la lecture du document pour construire l'arbre DOM en mémoire, cette mise en forme produit autant de noeuds "Text". Nous le verrons plus loin, les langages de programmation proposent souvent des options lors du chargement pour supprimer automatiquement les noeuds "vides", c'est-à-dire uniquement composés d'espaces, de tabulations ou de retours à la ligne.
Asimov Isaac 1920-01-02 1992-04-06 Russe/Américain Liste des ouvrages Un défilé de robots I, robot Le robot qui rêvait
De nombreuses autres classes sont disponibles en DOM pour représenter les différents concepts présents dans un document XML. Dans les concepts structurants d'un arbre XML, nous n'avons pas encore évoqué l'instruction de traitement : "ProcessingInstruction".
interface ProcessingInstruction : Node {
readonly attribute DOMString target;
attribute DOMString data;
// raises(DOMException) on setting
};
D'autres classes DOM permettent de représenter des éléments de la DTD. Tout d'abord, la DTD elle-même est référencée par "DocumentType". Nous y trouvons la référence au document décrivant le schéma mais aussi les éventuelles déclarations d'entités ("Entity") et de notations ("Notation"). Dans notre exemple d'arbre "fil-rouge" ci-dessous, le noeud vert est un "DocumentType" et le noeud bleu est une "Entity". Ces entités peuvent être utilisées dans des textes. Elles seront alors à l'origine d'une division du texte pour placer un noeud "EntityReference".

interface DocumentType : Node {
readonly attribute DOMString name;
readonly attribute NamedNodeMap entities;
readonly attribute NamedNodeMap notations;
readonly attribute DOMString publicId;
readonly attribute DOMString systemId;
readonly attribute DOMString internalSubset;
};
interface Entity : Node {
readonly attribute DOMString publicId;
readonly attribute DOMString systemId;
readonly attribute DOMString notationName;
};
interface EntityReference : Node {
};
interface Notation : Node {
readonly attribute DOMString publicId;
readonly attribute DOMString systemId;
};
Enfin, la classe "Document" fait référence à une classe particulière appelée "DOMImplementation". Cette classe, indépendante d'une instance particulière de document, permet, à partir d'un "DocumentType" (qu'elle peut aussi créer), de construire un nouveau document.
interface DOMImplementation {
boolean hasFeature(in DOMString feature,
in DOMString version);
DocumentType createDocumentType(in DOMString qualifiedName,
in DOMString publicId,
in DOMString systemId)
raises(DOMException);
Document createDocument(in DOMString namespaceURI,
in DOMString qualifiedName,
in DocumentType doctype)
raises(DOMException);
};
Pour terminer, comme dans toute structure objet, DOM définit des exceptions particulières : "DOMException".
exception DOMException {
unsigned short code;
};
// ExceptionCode
const unsigned short INDEX_SIZE_ERR = 1;
const unsigned short DOMSTRING_SIZE_ERR = 2;
const unsigned short HIERARCHY_REQUEST_ERR = 3;
const unsigned short WRONG_DOCUMENT_ERR = 4;
const unsigned short INVALID_CHARACTER_ERR = 5;
const unsigned short NO_DATA_ALLOWED_ERR = 6;
const unsigned short NO_MODIFICATION_ALLOWED_ERR = 7;
const unsigned short NOT_FOUND_ERR = 8;
const unsigned short NOT_SUPPORTED_ERR = 9;
const unsigned short INUSE_ATTRIBUTE_ERR = 10;
const unsigned short INVALID_STATE_ERR = 11;
const unsigned short SYNTAX_ERR = 12;
const unsigned short INVALID_MODIFICATION_ERR = 13;
const unsigned short NAMESPACE_ERR = 14;
const unsigned short INVALID_ACCESS_ERR = 15;
Le standard W3C DOM est une structure objet en arbre permettant de structurer en mémoire un document XML. Elle permet une manipulation standard et assez facile des ressources XML (les similitudes PHP/Java des exemples de ce cours en sont un bon exemple, voir les sections suivantes), pour peu que l'on maîtrise le parcours des structures de données en arbre n-aire. La sémantique des classes, des attributs et des méthodes sont relativement intuitives. La représentation et la manipulation des ressources XML en mémoire est donc standardisée (normalisée). Le parcours des informations peut se faire quelque que soit leur position dans le document (même si la liste des fils d'un noeud est ordonnée selon la position des fils dans le document...).
Les spécificités de DOM amènent tout de même quelques contraintes. La principale est l'occupation mémoire. En effet, avant de pouvoir effectuer des traitements sur un document XML, il est indispensable qu'il soit chargé complètement en mémoire. Pour la construction de données spécifiques (objets métiers), l'information est donc en double. De plus, pour des traitements linéaires, travailler avec DOM revient à parcourir deux fois le document. Enfin, de manière plus anecdotique, la production de documents XML (sérialisation XML) n'est pas toujours aisée (en Java par exemple, nous le verrons dans la section suivante).
Les inconvénients que nous venons d'évoquer peuvent être résolus en utilisant une autre API que nous abordons dans une autre section : SAX. Cette dernière est même utilisée par les implémentations de DOM en Java pour créer la structure en mémoire.
NB - une fiche de synthèse fort utile en PDF : DOM-Level2-Core.
Dans cet exercice, le schéma de la ressource XML n'est pas important. La programmation doit en être indépendante.
Écrire une fonction en langage algorithmique utilisant l'API DOM qui, étant donnés un nom d'élément et la représentation DOM d'un document XML, compte le nombre d'occurrences de cet élément dans le document. Si possible, proposez plusieurs solutions.
Écrire une fonction en langage algorithmique utilisant l'API DOM qui, étant donnés un nom d'attribut, éventuellement une valeur pour cet attribut, et la représentation DOM d'un document XML, retourne les éléments possédant cet attribut (avec cette valeur).
![]()
Dans cet exercice, le schéma de la ressource XML est du XHTML (pour mémoire). Cependant, vous ne devez pas vous attacher à un schéma particulier. La seule chose importante est qu'il comporte un certain nombre de noeuds textes dont le contenu est correctement écrit en français. L'objectif est d'étiqueter, dans les noeuds textuels du document, toutes les occurrences d'un terme (par exemple, toutes les occurrences de "Nantes") par une balise (par exemple "<font color='darkred'/>").
Proposer un algorithme utilisant l'API DOM permettant d'entourer d'une balise (par exemple, la balise "ville") toutes les occurrences d'une chaîne de caractères donnée (ici, le nom d'une ville) dans un document représenté par un arbre DOM.
![]()
On suppose l'existence d'une fonction permettant de marquer les noeuds d'un arbre DOM. Ce marquage s'effectue par l'utilisation d'un attribut "marque" ayant la valeur "oui" lorsque le noeud est à conserver.
Dans le cadre de cet exercice, vous supposerez que (1) la racine du document est marquée et que (2) tout noeud qui a au moins un fils marqué est lui même marqué.
Écrire une fonction en langage algorithmique utilisant l'API DOM, qui construit une copie d'un arbre DOM marqué, mais en ne conservant que les éléments marqués.
![]()
Notes
1. Interface Description Language (appelé aussi interface definition language), abrégé en IDL, est un langage voué à la définition de l'interface de composants logiciels, laquelle permet de faire communiquer les modules implémentés dans des langages différents. IDL est défini par l'OMG ([OMG]) et utilisé notamment dans le cadre d'applications CORBA.
2. Dans le pseudo-code, nous supposons que l'opérateur "PourTout" parcourt un ensemble ordonné ou un intervalle de valeurs dans l'ordre.
3. Dans le code présenté, la fonction "versXML(e)" permet d'afficher la valeur d'un noeud "e" en fonction de son type. Dans l'exemple précédent, un noeud "Element" est fourni. Ce sera donc la "valeur" de ce noeud qui sera affichée, c'est-à-dire la forme textuelle XML du noeud. Pour un noeud "Element", ce sera le sous arbre dont ce noeud est la racine.