DOM en PHP et Java1 DOM et PHP1.1 Respect de DOM et spécificitésDepuis PHP 5, la structure objet de PHP s'est grandement améliorée. Du coup, un certain nombre de librairies sont apparues. C'est le cas des librairies sur XML. PHP dispose désormais d'une librairie pour manipuler des ressources XML par DOM. Nous verrons dans une autre section que PHP propose aussi une API spécifique appelée SimpleXML, particulièrement pratique pour la lecture de documents XML. En PHP, les classes liées à DOM sont préfixées par les trois lettres "DOM". En dehors de cette variante syntaxique, elles sont assez fidèles au standard du W3C que nous venons de présenter dans la section précédente. Comme dans tout langage, cette bibliothèque possède quelques spécificités que nous allons survoler ici. |
Tout d'abord, la classe DOMDocument possède des méthodes pour valider le document XML, que ce soit avec une DTD (validate()), une schéma XML-Schema (schemaValidate()) ou un schéma Relax NG (relaxNGValidate()). Ces validations ne se font qu'après le chargement du document. Pour faire une validation par DTD durant le chargement, il faut positionner l'attribut validateOnParse à "true" (il est à "false" par défaut). La validation est indispensable pour pouvoir utiliser la méthode getElementById. Cette dernière fonction peut être utilisée sur un document construit par le programme. Seulement, il faut être attentif à préciser les attributs identifiants, en utilisant la méthode setIdAttribute.
Dans cette même classe, se trouvent aussi des méthodes permettant le chargement et l'enregistrement d'un document XML :
"saveXML" peut prendre en paramètre un noeud du document. Ceci permet de ne visualiser en XML que le sous-arbre dont ce noeud est racine. De plus, il est possible de demander que le document XML généré soit formaté en positionnant un indicateur formatOutput à "true" ou "false". Dans le même ordre d'idée, avant le chargement du document, il est possible d'indiquer la suppression ou non des noeuds comportant uniquement des caractères de séparation (sur l'attribut preserveWhiteSpace, positionné à "true" par défaut). Positionner ce dernier à "false" permet d'optimiser de manière notable la parcours de l'arbre DOM.
Pour terminer avec DOMDocument, cette classe dispose aussi d'une méthode xinclude() pour traiter (ou non) les éléments/attributs du dialecte XInclude.
Dans la classe DOMNode, les constantes décrivant le type des noeuds sont de la forme "XML_xxx" où "xxx" est la constante du standard.
Afin de faciliter l'écriture de parcours de documents mémorisés en DOM, PHP propose une classe fort utile [1] : DOMXPath. Construite sur un document en DOM, elle permet d'exécuter des requêtes XPath 1.0. Cette requête est absolue (sur tout le document) ou relative (sur un noeud donné en paramètre). La méthode query($xpath) retourne une DOMNodeList, résultat de la requête.
Pour terminer, PHP propose aussi une classe permettant de faire des traitements avec XSL : XSLTProcessor. Cette classe doit être associée à une feuille de style XSL. Pour cela, il suffit de charger cette feuille de style (en XML) avec DOM, de la positionner dans le moteurs XSLT (importStylesheet($xsl_dom)) puis de l'appliquer sur un document. Selon le type de transformation voulu, la méthode diffère. Ainsi, à partir d'un document en DOM, sera généré :
Sur le document "fil-rouge", l'objectif de ce premier exemple est simplement de compter le nombre d'ouvrages édités depuis 1960. Nous allons présenter plusieurs solutions équivalentes du point de vue du résultat.
Remarques :
Avec cette première version, nous avons choisi de parcourir l'arbre DOM de manière systématique à la recherche d'éléments "livre", ayant un attribut "année" avec une valeur intéressante.
<?php
function compter($node) {
$nb = 0;
if ($node->nodeType == XML_ELEMENT_NODE) {
if ($node->tagName == "livre")
if ($node->getAttribute('annee')>1960)
$nb = 1;
}
if ($node->hasChildNodes()) foreach($node->childNodes as $fils) {
$nb += compter($fils);
}
return $nb;
}
$doc = new DOMDocument();
$doc->load("ex_asimov.xml");
echo compter($doc->documentElement);
?>
NB : Le même exemple en Java.
Cette seconde version ne diffère que de très peu de la version précédente. Elle montre qu'il est possible d'exploiter la structure du document pour limiter le parcours de l'arbre. Cette version n'est qu'un premier pas. Il est évidemment possible de faire beaucoup mieux pour optimiser le parcours.
<?php
function compter($node) {
$nb = 0;
if ($node->nodeType == XML_ELEMENT_NODE) {
if ($node->tagName == "livre") {
if ($node->getAttribute('annee')>1960) $nb = 1;
} else if ($node->hasChildNodes()) foreach($node->childNodes as $fils) {
$nb += compter($fils);
}
}
return $nb;
}
$doc = new DOMDocument();
$doc->load("ex_asimov.xml");
echo compter($doc->documentElement);
?>
Évidemment, il est possible de procéder différemment est utilisant la méthode de la classe Document : "getElementsByTagName()" qui va retrouver tous les éléments "livre" [2]. Ensuite, il suffit de parcourir les éléments trouvés pour rechercher ceux ayant une année satisfaisante.
<?php
$doc = new DOMDocument();
$doc->load("ex_asimov.xml");
$NodeList = $doc->getElementsByTagName('livre');
$nb = 0;
foreach($NodeList as $livre) {
if ($livre->getAttribute('annee')>1960) $nb += 1;
}
echo $nb;
?>
Pour terminer, plutôt que de construire un code PHP lourd, pourquoi ne pas utiliser XPath ? Dans ce dialecte, notre recherche s'écrit alors simplement : "/auteur/livre[@annee>1960]". Il suffit ensuite de compter le nombre d'éléments obtenus.
<?php
$doc = new DOMDocument();
$doc->load("ex_asimov.xml");
$xpath = new DOMXpath($doc);
$NodeList = $xpath->query('/auteur/livre[@annee>1960]');
$nb = $NodeList->length;
echo $nb;
?>
Ce second exemple est une variante du précédent. Il n'est plus question ici de compter les livres, mais de les récupérer sous forme d'un document XML.
La première solution consiste à construire un arbre DOM résultat, puis de l'enregistrer.
<?php header('Content-type: text/xml');
$doc = new DOMDocument();
$doc->load("ex_asimov.xml");
//Création du document résultat
$res = new DOMDocument('1.0', 'utf-8');
$res->formatOutput = true;
$racine = $res->createElement('liste-livres');
$res->appendChild($racine);
//Recherche des livres
$NodeList = $doc->getElementsByTagName('livre');
//Pour chaque livre, s'il est intéressant, l'ajouter dans l'arbre résultat
foreach($NodeList as $livre) {
if ($livre->getAttribute('annee')>1960) { //il est intéressant
$livre_res = $res->createElement('livre');
$racine->appendChild($livre_res);
$livre_res->setAttribute('annee', $livre->getAttribute('annee'));
$titre = $livre->getElementsByTagName('titre')->item(0);
$livre_res->setAttribute('titre', $titre->firstChild->wholeText);
}
}
//Afficher l'arbre résultat
echo $res->saveXML();
?>
Ce code donnera le résultat ci-dessous.
<?xml version="1.0" encoding="utf-8"?> <liste-livres> <livre annee="1964" titre="Un défilé de robots"/> <livre annee="2002" titre="Le robot qui rêvait"/> </liste-livres>
NB : Le même exemple en Java.
Cependant, assez souvent (dans les cas simples), il n'est pas nécessaire de construire l'arbre DOM résultat. Si ce résultat n'est pas retravaillé par la suite, il suffit de construire la chaîne de caractères formant le XML résultat. Le code ci-dessous est conçu avec cette hypothèse.
<?php header('Content-type: text/xml');
$doc = new DOMDocument();
$doc->load("ex_asimov.xml");
//Création du début du document résultat
$res = '<?xml version="1.0" encoding="utf-8"?> ';
//Recherche des livres
$NodeList = $doc->getElementsByTagName('livre');
//Pour chaque livre, s'il est intéressant, l'ajouter dans l'arbre résultat
foreach($NodeList as $livre) {
if ($livre->getAttribute('annee')>1960) { //il est intéressant
$res .= '<livre ';
$annee = $livre->getAttribute('annee');
$res .= "annee='$annee' ";
$titre = $livre->getElementsByTagName('titre')->item(0);
$titre_livre = $titre->firstChild->wholeText;
$res .= "titre='$titre_livre'/>\n";
}
}
//Création de la fin du document résultat
$res .= '</liste-livres>';
//Afficher l'arbre résultat
echo $res;
?>
Java possède aussi une bibliothèque XML/DOM. C'est le paquetage org.w3c.dom. A chaque classe de la spécification DOM correspond une interface Java. Par exemple, la classe Node est définie comme dans org.w3c.dom.Node.
Attention, Java n'est pas capable de gérer l'accès aux attributs d'une classe de manière aussi souple qu'IDL. C'est le cas de la propriété "en lecture seule" par exemple. Aussi, les attributs des classes DOM ne sont accessibles en Java que par l'intermédiaire de méthodes d'accès : "get/set" (accès libre) ou "get" (accès en lecture seule). Par exemple, l'attribut DOM de la classe Node en lecture seule "nodeType" n'est accessible qu'uniquement par la méthode Java getNodeType(). Au contraire, l'attribut en accès libre "nodeValue" est accessible par les méthodes getNodeValue() et setNodeValue(). Une implémentation doit donc être choisie (Xerces-J, JAXP...), mais une implémentation par défaut est disponible (issue de JAXP) : javax.xml.parsers.
Contrairement à PHP, les procédures de chargement et de sauvegarde de documents XML ne sont totalement encapsulées en Java. Nous allons regarder plus en détail ces deux phases.
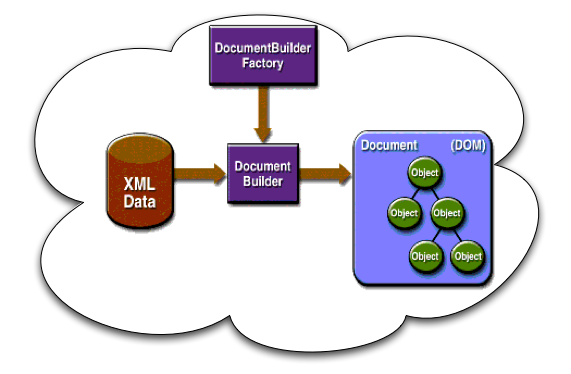
Le principe de chargement d'un document vers une structure DOM en Java est illustrée par la figure ci-dessous. IL convient d'abord d'accéder au DocumentBuilderFactory. Ce dernier fournit un DocumentBuilder qui sera chargé de la construction effective et de produire un "DOMImplementation" pour créer de nouveaux documents.
Ainsi, un code classique en Java devrait contenir la partie de code ci-dessous pour récupérer (charger) ou créer des document XML par DOM.
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
...
class visu_dom {
public Document doc;
...
public void load(String fichier) {
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
doc = db.parse(fichier);
} catch(Exception e) {System.out.println("Exception !");System.exit(0);}
}
...
public static void main(String argv[]) {
visu_dom vs = new visu_dom();
vs.load("ex_asimov.xml");
...
}
}
Le "DocumentBuilderFactory" est en mesure de proposer un "DocumentBuilder" ayant certaines propriétés comme la validation du document (DTD ou XML-Schema), la gestion des éléments/attributs XInclude, etc. Pour cela, il faut utiliser les méthodes suivantes :
setIgnoringComments(boolean ignoreComments) setIgnoringElementContentWhitespace(boolean whitespace) setNamespaceAware(boolean awareness) setSchema(Schema schema) setValidating(boolean validating) setXIncludeAware(boolean state)
L'enregistrement d'une structure DOM vers un document XML est encore plus délicate. En fait, plusieurs solutions sont envisageables. Nous allons en évoquer ici deux.
La première solution consiste à faire intervenir des classes issues d'un paquetage de la fondation Apache, en particulier de Xerces-J. Elle utilise principalement la classe XMLSerializer (pour générer un flux) et la classe OutputFormat (pour formater le flux en XML, HTML, etc.).
import org.apache.xml.serialize.XMLSerializer;
import org.apache.xml.serialize.OutputFormat;
import java.io.FileOutputStream;
import java.io.IOException;
import org.w3c.dom.Document;
...
class visu_dom {
public Document doc;
...
public void save(String fichier) {
try{
XMLSerializer ser = new XMLSerializer(new FileOutputStream(fichier),
new OutputFormat(doc));
ser.serialize(doc);
}catch(IOException e){System.out.println("Exception !");System.exit(0);}
}
...
public static void main(String argv[]) {
visu_dom vs = new visu_dom();
...
vs.save("ex_asimov2.xml");
}
}
Cette solution, bien que classique, est maintenant désuète ("Deprecated"). En utilisant l'API de transformation de JAXP, il est possible de détourner la classe permettant de faire des transformations XSL (Transformer). En effet, la transformation par défaut est l'identité (on laisse tel que c'est). Ensuite, il suffit d'indiquer le format de sortie (OutputKeys), et le tour est joué. Ceci donne alors l'exemple ci-dessous.
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
...
public void save(String fichier, Document doc) {
try {
// Création d'un transformateur (XSL) "identité",
// ne faisant rien sur le document XML lui-même
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer();
transformer.setOutputProperty(OutputKeys.METHOD, "xml");
if (doc.getDoctype() != null){
String systemValue = (new File(doc.getDoctype().getSystemId())).getName();
transformer.setOutputProperty(OutputKeys.DOCTYPE_SYSTEM, systemValue);
}
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
DOMSource source = new DOMSource(doc);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
} catch (TransformerConfigurationException tce) {
// Erreur générée par le générateur de transformateurs
System.out.println("* Transformer Factory error");
System.out.println(" " + tce.getMessage());
Throwable x = tce;
if (tce.getException() != null)
x = tce.getException();
x.printStackTrace();
} catch (TransformerException te) {
// Erreur générée par le transformateur
System.out.println("* Transformation error");
System.out.println(" " + te.getMessage());
Throwable x = te;
if (te.getException() != null)
x = te.getException();
x.printStackTrace();
}
}
Bien évidemment, comme en PHP, la "sérialisation" peut être faite simplement en écrivant le XML dans un fichier texte lors d'un parcours de l'arbre DOM.
Pour illustrer l'utilisation de DOM en Java, nous allons reprendre le même exemple qu'avec PHP : le nombre de livre depuis 1960. En prenant la version de base (code ci-dessous), le code est extrêmement similaire à celui en PHP.
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
class nbl_dom {
public Document doc;
public int compter(Node n) {
int nb = 0;
if (n.getNodeType()==Node.ELEMENT_NODE) {
Element el = (Element)n;
if (el.getTagName()=="livre")
if (Integer.parseInt(el.getAttribute("annee"))>1960)
nb = 1;
}
NodeList nl = n.getChildNodes();
for(int i=0;i<nl.getLength();i++) {
nb = nb + compter(nl.item(i));
}
return nb;
}
...
public static void main(String argv[]) {
nbl_dom nbl = new nbl_dom();
nbl.load("ex_asimov.xml");
System.out.println(nbl.compter(nbl.doc.getDocumentElement()));
}
}
De la même manière, le second exemple consistant à générer un document XML est très similaire avec la version PHP.
...
public Document compter() {
NodeList nl = doc.getElementsByTagName("livre");
Document res=null;
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
DOMImplementation impl = builder.getDOMImplementation();
res = impl.createDocument(null,null, null);
Element racine = res.createElement("liste-livres");
res.appendChild(racine);
for (int i = 0; i < nl.getLength(); i++) {
Element el = (Element) nl.item(i);
if (Integer.parseInt(el.getAttribute("annee")) > 1960) {
Element livre = res.createElement("livre");
racine.appendChild(livre);
livre.setAttribute("annee", el.getAttribute("annee"));
Element titre = (Element)el.getElementsByTagName("titre").item(0);
livre.setAttribute("titre", titre.getFirstChild().getNodeValue());
}
}
} catch (FactoryConfigurationError e) {
System.out.println("Could not locate a JAXP DocumentBuilderFactory class");
} catch (ParserConfigurationException e) {
System.out.println("Could not locate a JAXP DocumentBuilder class");
}
return res;
}
...
DOM est un standard du W3C permettant de manipuler des ressources XML (section précédente). A ce jour, quasiment tous les langages de programmation possèdent des API permettant de mettre en oeuvre ce standard. Comme nous l'avons vu dans cette section, les langages implémentent les spécifications DOM en fonction de leurs particularités (cas de Java avec les attributs). Cependant, les programmes sont souvent très similaires, comme l'a montré notre exemple. Au spécifications du standard sont souvent ajoutées des méthodes de lecture et écriture de fichiers XML, mais aussi de traitement de code en XPath ou en XSLT.
En revanche, ce standard impose des spécificités qui ne permettent pas toujours d'exploiter au mieux le langage. Aussi, assez souvent, sont proposées des API "proches", c'est-à-dire dans l'esprit de DOM, mais exploitant au mieux les particularités du langage. Nous verrons, dans une prochaine section, un tel exemple avec JDOM en Java.
NB - une fiche de synthèse fort utile en PDF : DOM-Level2-Core.
Les exercices présentés ici se baseront, pour la plupart, sur un même contexte. La DTD edt.dtd est un modèle pour des documents qui mémorisent l'emploi du temps d'un groupe d'étudiants au cours d'une année universitaire. Un exemple est présenté dans edt1213.xml. Cet exemple est proposé pour apprendre à manipuler DOM. Il n'est en rien réaliste et doit être pris tel que, comme un simple contexte d'exercice.
En utilisant en PHP/DOM (sans XPath) pour le traitement, donner le nombre de cours (les créneaux sans distinction de type) pour une matière pour la semaine donnée.
Remarque : la semaine et la matière attendues sont données en GET (il n'est pas nécessaire de contrôler la présence et la validité).
![]()
En utilisant en PHP/DOM (sans XPath) pour le traitement, donner l'emploi du temps pour une matière pour la semaine donnée selon la DTD semaine1.dtd. Le résultat, produit par des "echo", devra afficher tous les jours présents dans l'emploi du temps.
Remarques :
Par exemple, si l'on veut l'emploi du temps en semaine 12 pour "Projet XML", il faut entrer l'URL "http://.../semaine_dom.php?no=s12&matiere=Projet%20XML". Cela doit produire le document ci-dessous.
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE emploi-du-temps SYSTEM "../xml/semaine1.dtd">
<emploi-du-temps semaine='s12' matière='Projet XML'>
<jour nom='lu' date='19/03/2007'>
</jour>
<jour nom='me' date='21/03/2007'>
<enseignement code-plage='c3' type='TP'/>
</jour>
<jour nom='je' date='22/03/2007'>
<enseignement code-plage='c2' type='TP'/>
<enseignement code-plage='c3' type='TP'/>
</jour>
<jour nom='ve' date='23/03/2007'>
</jour>
</emploi-du-temps>
Modifier le code PHP de l'exercice précédent pour que le résultat soit construit en DOM avant d'être affiché.
![]()
Reprendre l'exercice 2, mais seuls les jours de la semaine, concernés par la matière, doivent être présents.
![]()
Reprendre l'exercice 2, mais tous les jours de la semaine doivent être présents, même ceux où il n'y a pas le cours demandé.
![]()
Soit la nouvelle DTD semaine2.dtd. Dans cette nouvelle version, le code de la plage (pour un créneau) est remplacé par l'heure de début.
Reprendre l'exercice 2, mais avec celle nouvelle DTD.
![]()
Reprendre l'exercice 3, mais l'utilisation de XPath est autorisée.
![]()
Reprendre l'exercice 2, en Java/DOM.
![]()
Notes
1. Attention à l'utilisation de la classe DOMXPath ! C'est une évidence qu'il est bon de rappeler : l'utilisation d'un langage supplémentaire (XPath) demande tout un processus d'interprétation ou de compilation qui sera chronophage. Aussi, dans des applications pour lesquelles le temps de réponse est un élément sensible, voire central, l'utilisation de XPath est intéressante pour le développement d'une maquette, mais il faudra ré-écrire toute la recherche en DOM de base pour la mise en exploitation.
2. Comme dans la note précédente, il est indispensable de garder à l'esprit que cette méthode est générique. Aussi, elle va parcourir l'arbre à la recherche de l'élément sans aucune optimisation. Bien que plus courte que les précédentes, cette version est donc identique à la première.