

Aussi, dès la sortie de XML, le W3C à proposé un langage permettant de faciliter ces tâches : XPath ou XPath 1.0 (http://www.w3.org/TR/xpath). Plus récemment, ce langage a été enrichi dans son expressivité et dans les fonctions qu’il propose : c’est XPath 2.0 (http://www.w3.org/TR/xpath20/).
Dans ce chapitre, nous allons nous intéresser à XPath dans ses deux versions XPath 1.0 et XPath 2.0. Nous prolongerons cette notion de localisation du XML par trois autres standard dédiés à l'organisation de ressources XML : XLink, XPointer et XInclude.
Pour bien comprendre le fonctionnement de XPath, il faut d’abord bien comprendre la structure d’un document XML. Pour mémoire, un document XML ne possède qu’un seul élément racine. De plus, tout élément doit respecter la règle d’inclusion stricte dans un seul élément (sauf pour la racine bien évidemment). Un document XML peut donc être considéré comme une structure hiérarchique de type «arbre» (au sens de la représentation informatique, c’est-à-dire racine en haut et feuilles en bas). Tous les éléments, mais aussi les commentaires, les textes, etc., sont alors considérés comme des noeuds de l’arbre. Chaque noeud possède des relations avec ceux qui l’entourent. Le noeud dans lequel il se trouve est le noeud «parent». Les noeuds qu’il contient sont des noeuds «fils». Les noeuds qui sont dans le même parent sont des noeuds «frères» («frères ainés» s’ils sont avant lui dans le document - à gauche sur la représentation - et «frères cadets» s’ils sont après lui). Les éléments contenus dans un élément sont, en effet, ordonnés (selon l’ordre d’apparition dans le document). Un élément vide, un commentaire, une instruction de traitement, un texte, etc. sont des noeuds «feuilles» (sans fils).
Attention, l’arbre «XML» associé à un document XML est dit «résolu» :
Dans un arbre XML résolu, 7 types de noeuds peuvent être identifiés :
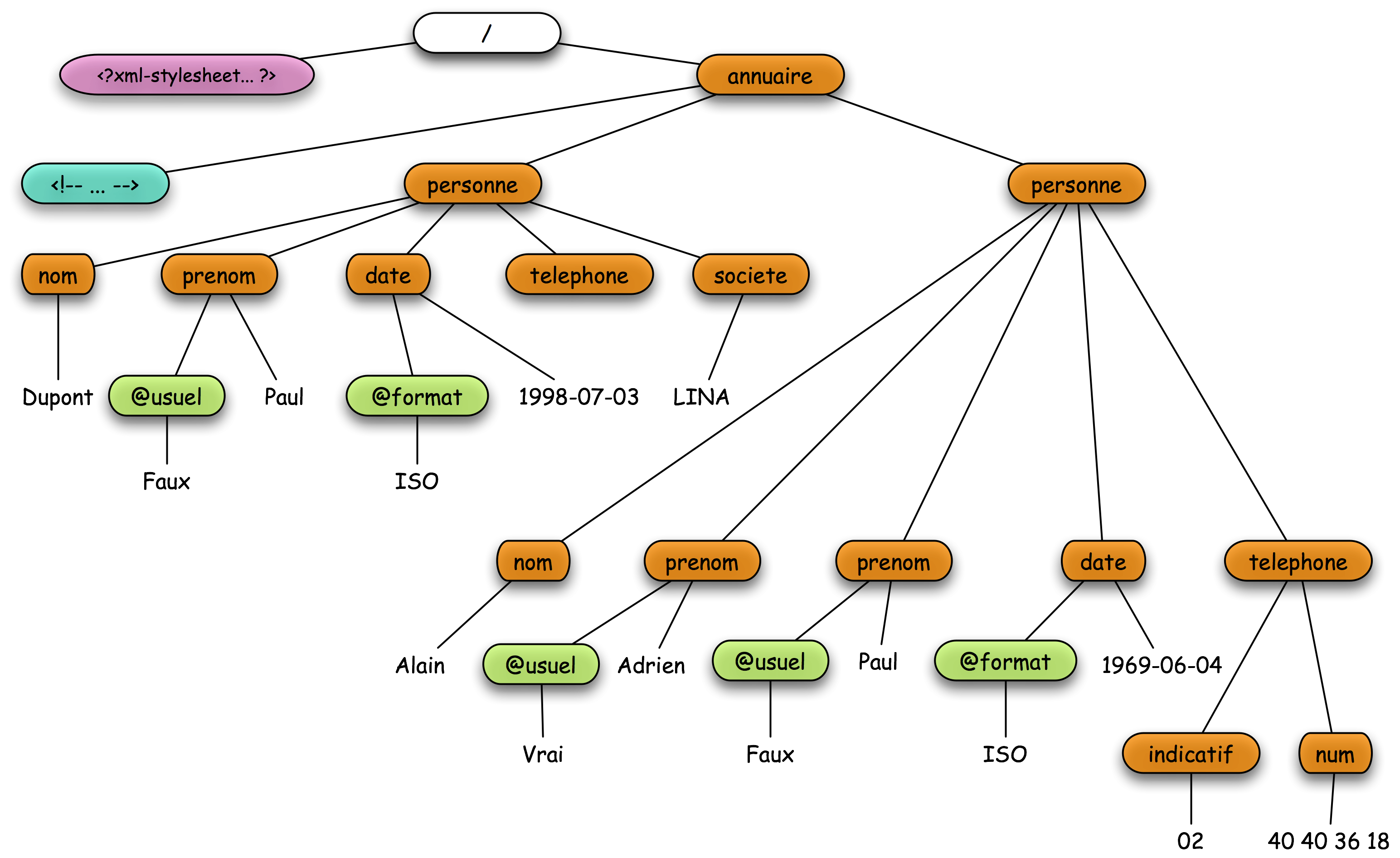
Afin de présenter la manipulation de XPath, nous allons utiliser un même exemple "fil-rouge". Notre document XML de référence décrit un annuaire d’entreprise simple. La DTD et un exemple de document sont présentés ci-dessous.
| |
|
Ce document engendre l’arbre XML résolu ci-dessous. Il est à noter la «perte» de la référence à la DTD.
|
Pour bien aborder ce chapitre, il est nécessaire d'avoir les pré-requis suivants :
|
Légende :
|
Cet enseignement a pour objectifs que l'étudiant soit capable de comprendre les mécanismes de localisation et de recherche en XML. Il devra être capable d'exploiter ces connaissances dans le cadre des dialectes XML qui utilisent XPath.