|
|
XPath
1. Introduction à XPath
XPath est un langage non-XML (comme les DTD), qui permet d’identifier et localiser des parties d’un document XML, et de sélectionner des noeuds et des ensembles de noeuds (sous-arbres) dans une arborescence XML résolue. Son principe est assez simple : il décrit des chemins à prendre pour aller de la racine (ou d’un noeud «local») vers le noeud recherché en suivant les filiations. Ce langage simple est utilisé de manière indépendante pour faire des recherches dans un document XML ou comme outil dans d’autres dialectes XML (XPointer, XLink, XSLT, XQuery, XForms, etc.).
|
2. Syntaxe
2.1 Chemin de localisation
XPath est donc un chemin de localisations, c’est-à-dire une suite d’étapes de localisation séparées par un symbole «/». Le chemin est dit «absolu» s’il commence à la racine et «relatif» (au noeud contextuel) dans le cas contraire. Ce chemin désigne un ensemble, éventuellement vide, de noeuds de l’arbre, autrement dit, de structures XML, de valeurs numériques ou de valeurs textuelles.
Une étape de localisation est constituée d’un axe, d’un test de noeud et d’un prédicat selon la syntaxe suivante : «axe::test[prédicat]». L’«axe» est une relation structurale désignant le prochain ensemble de noeuds (direction à prendre dans l’arbre). Le «test» désigne un type de noeud (élément ou attribut). Le «prédicat», optionnel, permet de mettre en place des filtres sur les noeuds candidats obtenus par le «test» et l’«axe». Pour se donner une idée de ce qu’est XPath, voici deux exemples :
/child::annuaire/child::personne[child::nom/child::text()="Dupont"]/child::prenom
ou
/annuaire/personne[nom='Dupont']/prenom
Ces deux requêtes sont identiques (et donc qui donnent le même résultat), sauf que la seconde utilise une syntaxe alternative plus simple mais moins expressive ; elles partent de la racine et prennent la direction du seul «fils» du document, la racine ; ensuite, elles se dirigent vers les fils pour prendre les éléments «personne» qui doivent avoir la particularité d’avoir un fils «nom» ayant un contenu «Dupont» ; enfin, elles se dirigent vers les fils «prenom» qui se trouvent sélectionnés ; le résultat de ces requêtes est donc l’élément : «<prenom usuel=‘Faux’>Paul</prenom>» ;/annuaire/personne[nom='Dupont']/prenom/text()
Cette requête prend le même chemin que les précédentes, mais va un pas plus loin : elle ne prend en compte que le noeud texte compris dans «prenom» et non pas tout l’élément ; le résultat est donc le noeud texte : «Paul».
Attention, les exemples qui précédent peuvent porter à croire que seul un chemin en pris. Ce n’est pas vrai. Lorsque plusieurs noeuds sont candidats, toutes les possibilités sont «explorées en parallèle». Le résultat est alors une liste de noeud.
2.2 Axes
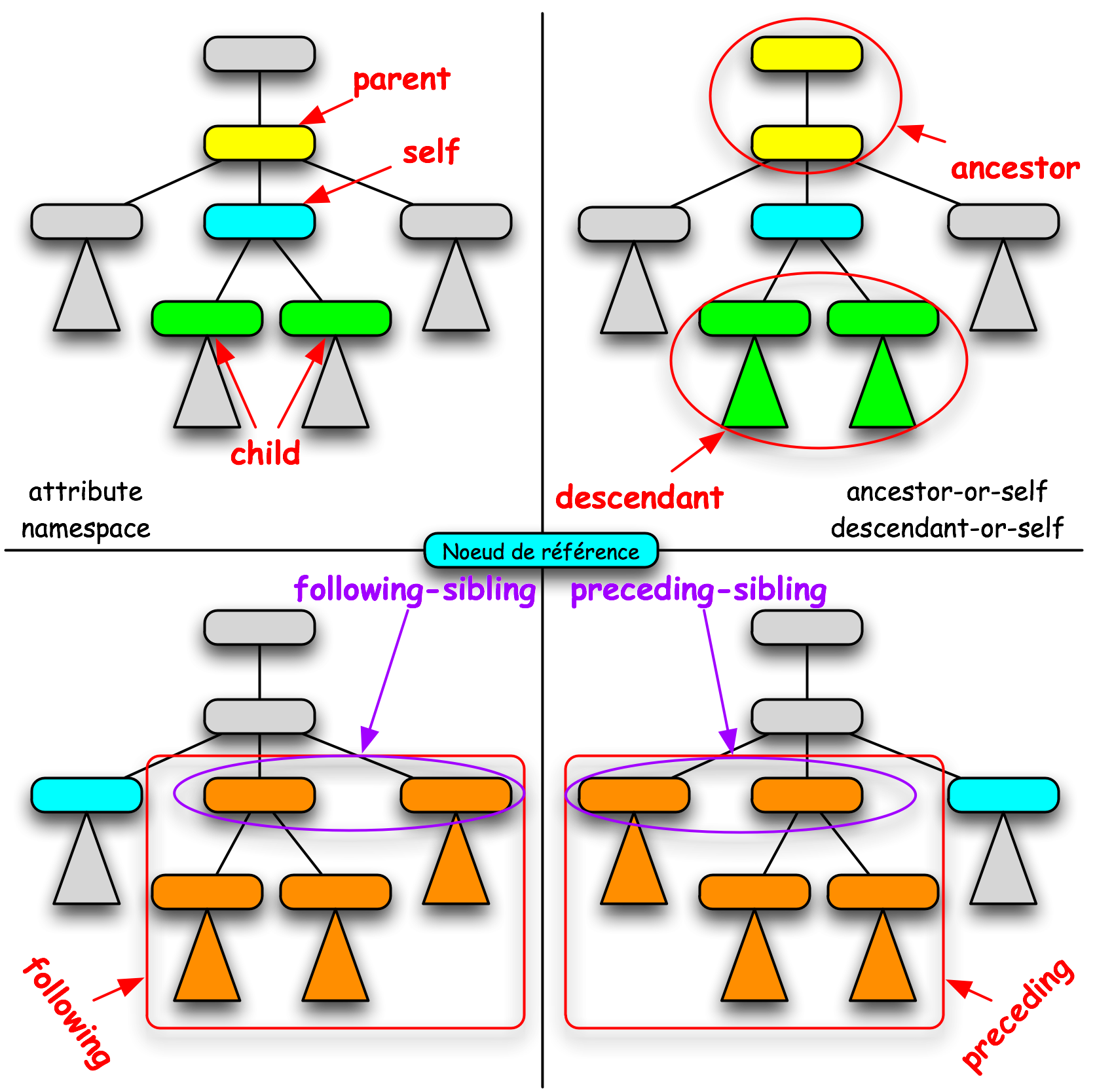
Un certain nombre de mots-clés permettent «de circuler dans l’arbre XML». La figure ci-contre les illustre. Soit un noeud de référence (en bleu) qui est un noeud sur lequel on est arrivé grâce aux étapes précédentes.
Plusieurs axes sont possibles :
- «parent» : remonte dans le noeud «parent» ;
- «child» : descend explorer les fils ;
- «self» : reste sur le noeud courant ;
- «attribute» : part explorer les attributs du noeud ;
- «following» : explore les noeuds des sous-arbres dont les frères cadets sont les racines ;
- «following-sibling» : explore les frères cadets (mais pas leurs fils) ;
- «ancestor-or-self» : explore tous les noeuds entre le noeud racine et le noeud de référence (ce dernier compris) ;
- etc.
|
|
2.3 Tests de noeuds
Une fois la direction indiquée, il faut spécifier le type de noeud à prendre en compte : élément, texte, commentaire, instruction ou espace de noms. Pour les éléments, il est aussi possible d’être plus précis en donnant le nom de l’élément attendu. Il en est de même pour les attributs selon l’axe choisi. Ainsi, le test peut prendre une des formes suivantes :
- «nom» : élément ou attribut XML (selon l’axe choisi) nommé «nom» ;
- «*» : tous les éléments ou attributs XML possibles ;
- «text()» : les noeuds texte ;
- «comment()» : les commentaires ;
- «processing-instruction()» : les instructions de traitement ;
- «processing-instruction(ip)» : les instructions de traitement dont la cible est «ip» ;
- «node()» : tous les noeuds possibles de l’arbre XML (éléments, CDATA, attributs, commentaires...).
Pour illustrer, voici quelques exemples de couples «axe::test», en supposant qu’un noeud «n» est sélectionné :
- «child::personne» : tous les éléments XML fils de «n» nommés «personne» ;
- «child::*» : tous les éléments XML fils de «n» ;
- «child::text()» : tous les noeuds fils texte de «n» ;
- «child::node()» : tous les noeuds fils de «n», quelque soit leur type ;
- «attribute::*» : tous les attributs du noeud «n» ;
- «descendant::personne» : tous les noeuds «personne» présents dans la descendance du noeud «n» ;
- «following-sibling::personne» : les éléments «personne» fils des frères cadets du noeud «n» (même père et après dans le document XML !).
2.4 Syntaxe abrégée
L’écriture de chemins XPath telle qu’ils sont présentés ci-dessus est souvent lourde et peu lisible. Aussi, pour faciliter l’utilisation de XPath, un écriture simplifiée est proposée. L’objectif est de simplifier l'écriture d'un chemin en prenant une syntaxe assez familière (en tout cas pour les informaticiens). En effet, elle se rapproche des commandes système de parcours des structures de fichiers et de répertoires.
Les simplifications sont les suivantes :
- «.» = «self::node()» ;
- «..» = «parent::node()» ;
- «nom» = «child::nom» ;
- «@attr» = «attribute::attr» ;
- «//» = «/descendant-or-self::node()/».
Voici deux exemples d’équivalence d’étapes de localisation utilisant la syntaxe abrégée :
Les simplifications sont peu nombreuses et ne couvrent pas tous les cas possibles. Ainsi, certaines recherches ne peuvent pas être complètement simplifiées. Cependant, il est autorisé de mélanger les syntaxes et d’utiliser la syntaxe étendue lorsque le syntaxe abrégée ne permet pas de décrire correctement l’étape de localisation.
Par exemples, voici quelques requêtes dont une ne peut pas se simplifier totalement :
/annuaire/personne/following-sibling::personne
Cette requête XPath recherche toutes les personnes, sauf celle qui est en premier ; ici, le résultat sera la seconde personne ;/annuaire/personne/prenom
Cette requête recense tous les prénoms de l’annuaire. Le résultat sera :
<prenom usuel=‘Faux’>Paul</prenom>
<prenom usuel=‘Vrai’>Adrien</prenom>
<prenom usuel=‘Faux’>Paul</prenom>
//telephone/indicatif
Cette dernière requête recense les indicatifs de téléphone présents à tout niveaux ; ici, le résultat sera : <indicatif>02</indicatif>
2.5 Prédicats
Sélectionner des noeuds de l’arbre en fonction de leur type, de leur position, voire de leur nom, ne suffit pas. Parfois, des critères sur des positions ou des valeurs sont importants. Aussi, XPath propose un mécanisme de filtre sur les noeuds sélectionnés après l’axe et le test. Ainsi, seuls les noeuds référencés par l'expression avant application du prédicat et vérifiant le prédicat sont conservés.
Le prédicat peut prendre différentes formes, mais c’est toujours une expression dépendante du noeud courant (celui sélectionné par le type et la direction choisie). Parmi les prédicats possibles, on trouve :
- une référence à un nom d’élément ou d’attribut (en chemin relatif) : c’est un test d’existence ;
- une valeur entière : c’est la position du noeud dans la fratrie ;
- un appel de fonction ;
- une conjonction («and») ou disjonction («or») d'expressions logiques (comparaisons, tests, etc.) ou de prédicats ;
- chemin ou union de chemins (opérateur "|") : là encore, c’est un test d’existence.
Pour illustrer ces prédicats, voici quelques exemples :
/annuaire/personne[2]/nom
Cette requête sélectionne le nom de la seconde personne de l'annuaire ; elle est équivalente à la requête suivante : /annuaire/personne[position()=2]/nom
/annuaire/personne[position()=last()]/nom
Elle désigne le nom de la dernière personne de l'annuaire dans le document XML ;//*[num | indicatif]
Elle retourne tous les éléments contenant soit un élément «num» soit un élément «indicatif» du document ; elle peut aussi s’écrire : //*[./node()=num or ./node()=indicatif]
//telephone[indicatif = '02']
Ce chemin XPath recense les téléphones dont l'indicatif est en 02 ; elle est équivalente à : //telephone[string(indicatif)='02']
ou encore à la requête
//telephone[indicatif/text()='02']
/annuaire/personne[prenom/@usuel]
Elle désigne seulement les personnes qui ont un prénom avec un attribut «usuel» (quelque soit sa valeur), sauf s'il existe une DTD qui propose une valeur par défaut auquel cas, toutes les personnes seraient systématiquement sélectionnées !
Le premier exemple ci-dessus illustre une des utilisations de XPath : désigner un élément ou un attribut d’un document XML. Cette notion de liens utilisant XPath est reprise dans les standard XLink et XPointer.
3. Types et fonctions XPath
Dans le cadre des prédicats, le standard XPath propose des fonctions permettant d’effectuer des recherches assez précises. Ces fonctions dépendent de certains types. En XPath, les structures sont typées de manière implicites. Il existe cinq types de «valeurs» :
- «boolean» : c’est un booléen ;
- «number» : c’est un nombre ;
- «node-set» : c’est un ensemble de noeuds de l’arbre ;
- «string» : c’est un chaîne de caractères ;
- «object» : type générique.
Certaines fonctions ou opérateurs étant spécifiques pour certains types, il existe des fonctions pour convertir une «valeur» d’un type vers un autres (fonctions de transtypage). Par exemple, il existe la fonction : «string string(object)» qui convertit une valeur quelconque en chaine de caractères ; par exemple, en l’appliquant sur un élément XML, elle retourne une chaîne de caractère qui est la mise bout à bout de tous les noeuds texte du sous-arbre, ainsi «string('tototutu')» retournera «tototutu». D’autres, de même principe existent pour les différents types.
Dans cet ensemble de fonctions standard [1], il est possible de trouver, par exemple, les fonctions suivantes :
- pour le type «node-set» :
- «number last()» : déjà rencontrée, elle indique le rang du dernier fils d’une fratrie,
- «number position()» : elle indique le rang du noeud dans la fratrie,
- «number count(node-set)» : elle donne le nombre d’éléments dans l’ensemble de noeud (ensemble qui peut être construit par une requête XPath absolue ou relative),
- «node-set id(object)» : fonction très utile qui retourne le noeud qui possède un attribut de type ID ayant la valeur passée en paramètre, si plusieurs valeurs sont en paramètre alors elle retourne la liste des éléments concernés,
- «string local-name(node-set?)», «string name(node-set?)», «string namespace-uri(node-set?)» : pour la gestion des espaces de noms ;
- chaînes de caractères :
- «string string(object?)» : déjà vue, elle retourne tous les noeuds texte du sous-arbre,
- «string concat(string, string, string*)» : met bout à bout toutes les chaînes de caractères,
- «string substring-before(string, string)», «string substring-after(string, string)», «string substring(string,number,number)» : extrait une partie de la chaîne de caractères,
- «string normalize-space(string)» : supprime les espaces en début et en fin et remplace les successions d’espaces par un seul espace,
- «number string-length(string)» : indique la longueur de la chaîne de caractères,
- «boolean starts-with(string, string)», «boolean ends-with(string, string)» : teste le début (resp. la fin) d’une chaîne de caractères,
- «boolean contains(string, string)» : teste le contenu d’une chaîne de caractères...
- booléens :
- «boolean not(object)», «boolean true()», «boolean false()» : fonctions permettant de mettre en place des expressions logiques,
- «boolean lang(string)» : teste la langue de l’élément (attribut «xml:lang»),
- «boolean boolean(object?)» ;
- nombres :
- «number number(object?)»,
- «number sum(node-set)»,«number floor(number)», «number ceiling(number)», «number round(number)»...
Remarque : certains paramètres sont optionnels (suivis d'un "?"). La fonction s'applique alors sur le noeud courant.
4. Conclusion
XPath est un petit langage permettant d'effectuer des recherches dans un document XML. C'est un langage assez puissant mais limité. En effet, il ne peut pas formater le résultat pour produire un document XML bien formé. De plus, il se limite à fournir un résultat d'un seul sous-arbre. On en peut en effet combiner des données en résultat dans des sous-arbres sans lien de parenté. Ces problèmes seront résolus grâce à XPath 2 et à XQuery.
Exercices et tests
Exercice 1
Soit la DTD "edition.dtd" décrivant une classe de documents dont "jailu.xml" est un exemple.
Construire l’arbre XML résolu pour le fichier “jailu.xml”.
En reprenant la DTD “edition.dtd”, donner l'expression XPath 1.0 référençant :
- les auteurs (proposez toutes les variantes possibles);
- les auteurs français ;
- le deuxième auteur ;
- les titres de livre qui contiennent la chaîne ’robot’ ;
- les ouvrages ayant été publiés en 1996 ;
- les auteurs ayant publiés en 1996 ;
- le titre des ouvrages d’Isaac Asimov.
Remarque : pour chacune de ces expressions, vous donnerez aussi le résultat retourné.

Exercice 2
Étant donné un paramètre "$nom", donner l'expression XPath permettant
de désigner tous les éléments frères du noeud courant de nom "$nom".
Exercice 3
Un élément est marqué lorsqu'il possède un attribut de nom "marque"
et dont la valeur est "oui". Autrement, il est considéré comme non marqué (pas d'attribut "marque"
ou un attribut "marque" ayant la valeur "non").
Donner l'expression XPath permettant de désigner les noeuds éléments marqués dont
aucun des ancêtres n'est marqué.